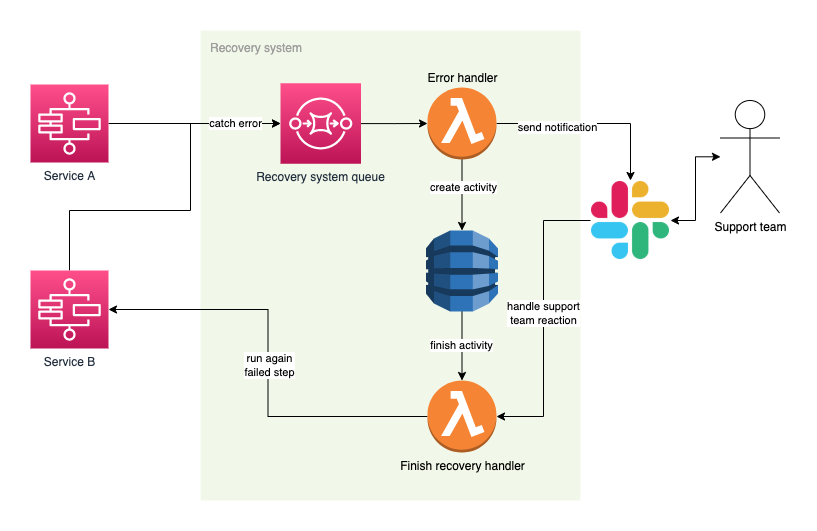
In the FinTech industry, which is our bread and butter, it is extremely important to design a system that is 100% resistant to unexpected errors. That's the reason why we created our so-called “Recovery Pattern” for AWS Step Functions that is implemented in all of our applications. Thanks to this pattern we can catch all errors generated within our systems and react to them asynchronously. At Purple Technology we have two teams dedicated to handling these issues, one team addresses technical issues and the other one problems with invalid clients input data which can not be validated programmatically.
Intro
We use Step functions to define all of our processes. This allows us to implement complex business requirements using interconnected functions with encapsulated functionality and have great visibility inside all the individual running processes. For such atomic functions we can define 2 levels of error processing:
- Retry statement within state machine definition
- The Recovery Pattern constructed via AWS Service Integration to handle Asynchronous actions
The Retry statement
The retry statement is good for use-cases when the error can be “fixed” by automatically re-invoking the function with a delay. Good example can be calling a 3rd party API with an error response 429 Too Many Requests.
Thanks to the retry statement our system can self-heal itself without involving any of our teams.
Recovery Pattern
For synchronously invoked functions we use AWS Service Integration Patterns feature to process errors that are then sent to the support team via Slack. The team is able to fix the issue and re-run the step again. During this time the execution is waiting for team's reaction which can be either “Run again” or “Reject”. If the support team fixes the problem and clicks on “Run again”, the failed step is invoked again and execution can continue in the defined flow. Let’s take a look at an example and go through it step by step.
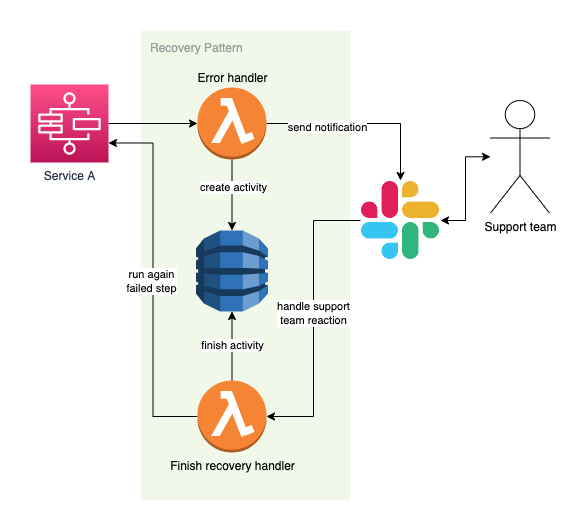
Example
Let’s implement the “Recovery Pattern” for an e-commerce order processing system inside which the product availability has to be checked using 3rd party API (step “Check availability”). Because this resource is not part of our system (in real world), we will implement the Recovery Pattern to make it resistant against unexpected outages (let's imagine your vendor API is under maintenance but you don't want to pause your service for your client's. Instead you want to be notified about a 3rd party outage and once it's up again, your system is able to run the task again). During any exception an execution will pause and wait for reaction from our support team via Slack.
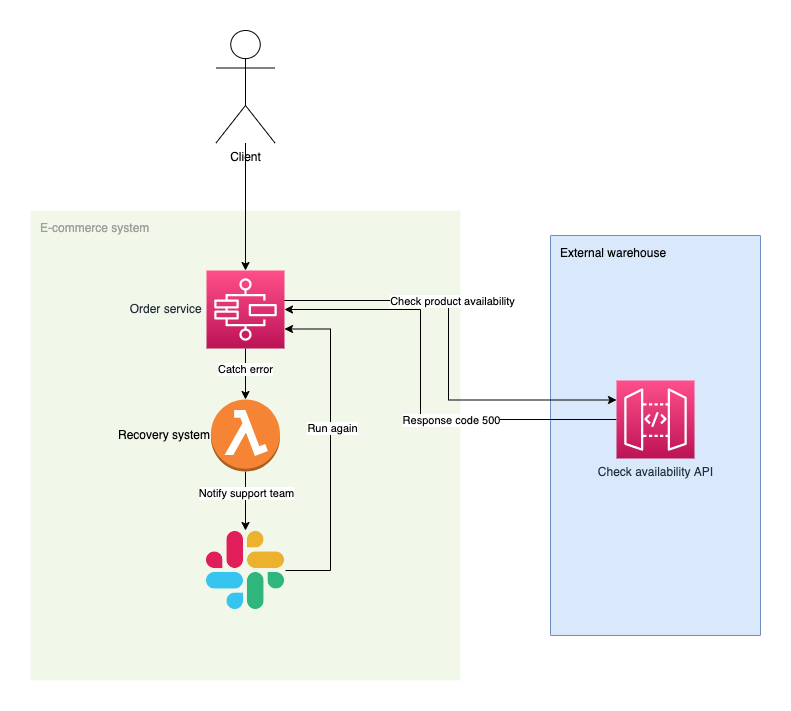
Code
First of all we need to create new order service
service: recoveries
plugins:
- serverless-step-functions
provider:
name: aws
runtime: nodejs14.x
region: eu-central-1We also need two tables. One for orders and the second one for recovery activities.
resources:
Resources:
OrdersTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: orders
AttributeDefinitions:
- AttributeName: orderId
AttributeType: S
KeySchema:
- AttributeName: orderId
KeyType: HASH
BillingMode: PAY_PER_REQUEST
RecoveriesTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: recoveries
AttributeDefinitions:
- AttributeName: executionId
AttributeType: S
KeySchema:
- AttributeName: executionId
KeyType: HASH
BillingMode: PAY_PER_REQUESTYou can see that I use executionId as HASH key so we can identify each recovery activity based on execution ID. For more complex use cases you will need to create a more sophisticated system to build HASH keys because of parallel and map flow, where one execution can generate multiple recovery activities at the same time.
We can’t use direct CloudFormation reference to the “Process Order” state machine in the IAM statement because it will cause circular dependency and because of that we have to construct the resource name manually.
provider:
...
environment:
ORDERS_TABLE_NAME: { "Ref": "OrdersTable" }
RECOVERIES_TABLE_NAME: { "Ref": "RecoveriesTable" }
iamRoleStatements:
- Effect: "Allow"
Action:
- dynamodb:PutItem
- dynamodb:GetItem
- dynamodb:DeleteItem
Resource: [{ "Fn::GetAtt": ["OrdersTable", "Arn"] }, { "Fn::GetAtt": ["RecoveriesTable", "Arn"] }]
- Effect: "Allow"
Action:
- states:SendTaskSuccess
- states:SendTaskFailure
Resource: { "Fn::Join": ["", ["arn:aws:states:", { "Ref": "AWS::Region" }, ":", { "Ref": "AWS::AccountId" }, ":stateMachine:ProcessOrderSM-*"]] }Now we can define a state machine that will process new orders and handle errors with the Recovery Pattern. Process Order state machine will be possible to invoke using API POST request.
stepFunctions:
validate: true
stateMachines:
processOrder:
id: ProcessOrderSM
events:
- http:
path: order
method: POSTBecause we want to focus on recovery pattern we will define a very simple order processing flow:
- create order in the database
- check product availability
- update order status to finish
stepFunctions:
...
definition:
StartAt: Create order record
States:
Create order record:
Type: Task
Resource: "arn:aws:states:::dynamodb:putItem"
Parameters:
TableName: { "Ref": "OrdersTable" }
Item:
orderId:
"S.$": $$.Execution.Id
item:
"S.$": $.item
status:
"S": CREATED
ResultPath: null
Next: Check availability
Check availability:
Type: Task
Resource: { "Fn::GetAtt": ["checkProductAvailability", "Arn"] }
Next: Update order record FINISHED
Update order record FINISHED:
Type: Task
Resource: "arn:aws:states:::dynamodb:updateItem"
Parameters:
TableName: { "Ref": "OrdersTable" }
Key:
orderId:
"S.$": $$.Execution.Id
ExpressionAttributeValues:
":s":
"S": FINISHED
ExpressionAttributeNames:
"#s": "status"
UpdateExpression: "set #s = :s"
ResultPath: null
End: true
functions:
checkProductAvailability:
handler: src/checkProductAvailability.handler
environment:
EXTERNAL_API: { "Fn::Join": ["", ["${self:custom.baseUrl}", "/external-api"]] }To simulate invocation 3rd party we will also create one more Lambda function hooked up to the API Gateway. Implementation is very easy and randomly returns internal error (status code 500).
'use strict'
module.exports.handler = async (event) => {
console.log(JSON.stringify(event))
if (Math.random() < 0.5) {
return {
statusCode: 500
}
}
return {
statusCode: 200,
body: JSON.stringify({ message: 'Product is OK' })
}
}Functions:
…
externalDummyAPI:
handler: src/externalDummyAPI.handler
events:
- http:
path: /external-api/{id}
method: GET
request:
parameters:
paths:
id: trueLet’s check what execution can look like in unexpected situations (keep in mind that external API to check product availability is not very reliable).
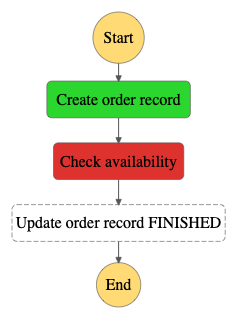
In this case, an order is created in the database and execution is finished with failed status. It’s not a very reliable system, right?
Since we want to keep our systems reliable, we will implement a recovery pattern for step Check availability.
First of all, I will add a retry definition for this step. So in this case every time Lambda checkProductAvailability throws any error, the state machine will make 2 retry attempts after waiting for 5 and 10 seconds.
Check availability:
Type: Task
Resource: { "Fn::GetAtt": ["checkProductAvailability", "Arn"] }
Retry:
- ErrorEquals: ["States.ALL"]
IntervalSeconds: 5
MaxAttempts: 2
Next: Update order record FINISHEDGreat! This can save lots of time and money because the state machine can autonomously handle unexpected errors and finish the order processing. But still, failed execution can occur in case of long term API outage.
So we will add a Catch block and send all errors to the recovery handler function. Let’s use the key lambdaFunctionError to pass data about error into the recovery handler. Every time we use the recovery pattern we have to create a new step (in this case "Check availability recovery") which invokes the recovery function and will wait for an answer. As payload we will pass input and also context to get execution ID and task token. The next step of this recovery step is again Check availability. Because I need to pause execution and wait for reaction, I add waitForTaskToken part into Resource.
...
Check availability:
Type: Task
Resource: { "Fn::GetAtt": ["checkProductAvailability", "Arn"] }
Retry:
- ErrorEquals: ["States.ALL"]
IntervalSeconds: 5
MaxAttempts: 2
Catch:
- ErrorEquals: ["States.ALL"]
Next: Check availability recovery
ResultPath: $.lambdaFunctionError
Next: Update order record FINISHED
Check availability recovery:
Type: Task
Resource: arn:aws:states:::lambda:invoke.waitForTaskToken
Parameters:
FunctionName: { "Fn::GetAtt": ["handleError", "Arn"] }
Payload:
Input.$: $
Context.$: $$
Next: Check availability
...Implementation of handleError Lambda function is very simple in this demo but in a production-ready system, we should implement more complex error processing. So we just save data about execution and error into the database and log messages into CloudWatch with an API address to try to check availability again. So once the support team fixes the problem in the external API, they can call this URL and execution will continue.
'use strict'
const AWS = require('aws-sdk')
const db = new AWS.DynamoDB.DocumentClient()
module.exports.handler = async (event) => {
const input = event.Input
const error = input.lambdaFunctionError
delete input.lambdaFunctionError
await db
.put({
TableName: process.env.RECOVERIES_TABLE_NAME,
Item: {
executionId: event.Context.Execution.Id,
step: event.Context.State.Name,
taskToken: event.Context.Task.Token,
input,
error
}
})
.promise()
console.log(
`New error handled. To run again go to ${process.env.FINISH_RECOVERY_API}/${event.Context.Execution.Id}?runAgain=true`
)
return input
}And how does the result look in a state machine designer?
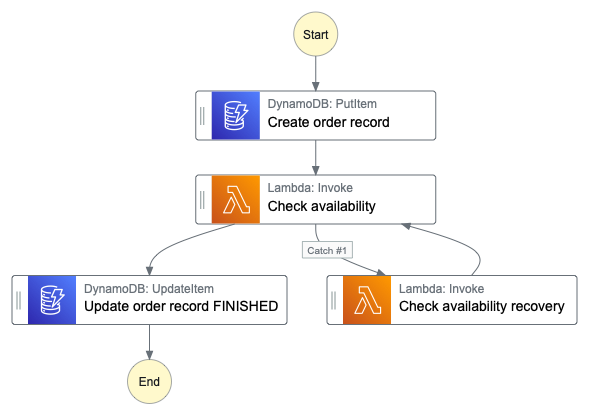
Successful execution
In successful execution an order is created in the database, availability is checked and at the end order status is updated to FINISHED.
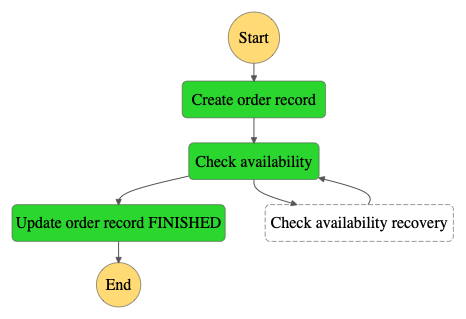
Execution with error
In use cases when external service is down order processing will pause and wait for support team reaction. They can run the check availability step again or stop execution. This functionality is done by the handleError Lambda function. This function creates a new activity in the database and logs a message in CloudWatch.
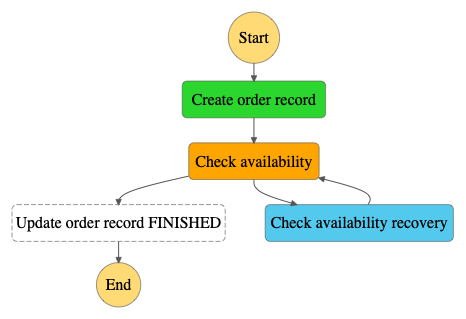

Once the problem is solved, the support team invokes finishRecovery function using API (API address is logged in CloudWatch per each error) and execution checks availability again.
Wrap up
Based on this pattern we can build very complex flows on the backend and have an overview about each exception.
This implementation was simplified as much as possible. Of course in real applications we can create more complex error handling. For example in Purple Technology we have one application just for handling all errors from production systems. Because of system decoupling we use Simple Queue Service (SQS) for collecting all errors. Once we handle an error we parse the error message and send a message to Slack channel.